


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
启发式的物品相似度传播的协同过滤算法研究*
引用本文
李琳娜, 李建春, 张志平. 启发式的物品相似度传播的协同过滤算法研究*. 现代图书情报技术, 2013, 29(1): 30-35
Li Linna, Li Jianchun, Zhang Zhiping. Research on Collaborative Filtering of Heuristic Transitive Similarity Between Items. New Technology of Library and Information Service, 2013, 29(1): 30-35
Permissions
Li Linna, Li Jianchun, Zhang Zhiping. Research on Collaborative Filtering of Heuristic Transitive Similarity Between Items. New Technology of Library and Information Service, 2013, 29(1): 30-35
启发式的物品相似度传播的协同过滤算法研究*
摘要
针对基于物品的协同过滤推荐方法只能发现具有共同用户打分的项目之间的相似关系的问题, 受到社会网络中人与人之间的信任关系具有传递性质的思想的启发, 认为物品之间的相似关系也具有相应的传递性并提出基于启发式的物品相似度传播的协同过滤推荐方法。最后通过实验验证该方法可以提高基于物品的协同过滤推荐方法的推荐质量。
关键词:
协同过滤; 相似网络; 稀疏性
Research on Collaborative Filtering of Heuristic Transitive Similarity Between Items
Abstract
Aiming at the problem of only finding similar relationship between items rated by common users and enlightened by the transitivity between peoples among social network, this paper figures that the similarity between items also have transitivity. A collaborative filtering algorithm based on heuristic similarity propagation between items is proposed. The experiments indicate that the proposed method can provide better recommendation accuracy by comparing with classic collaborative filtering algorithms.
Keyword:
Collaborative filtering; Similar network; Sparsity
1 引 言
协同过滤推荐技术自被提出以来, 就受到工业界和学术界的广泛关注。根据具体的推荐策略, 协同过滤算法又分为基于用户的协同过滤算法和基于物品的协同过滤算法[1]。基于用户的协同过滤算法为用户推荐与其偏好相似的用户喜欢的物品; 基于物品的协同过滤算法为用户推荐那些和他们之前喜欢的物品相似的物品。基于物品的协同过滤推荐算法是为了解决基于用户的协同过滤推荐算法的可扩展性和无法对推荐结果做出解释这两个问题而由亚马逊公司提出的推荐算法[2, 3, 4]。协同过滤推荐算法可以分为两类:基于记忆的算法和基于模型的算法[1, 5]。但已有一些研究和实验报道了基于模型的算法在推荐准确率方面要优于基于记忆的算法[6, 7]; 并且基于模型的算法实现起来比较简单, 不需要复杂的参数优化过程。这些特性使得其在实践中得到广泛的应用。但是一个新用户要想获得比较好的推荐结果, 其必须提供足够的对物品的打分信息。但是对具有较少物品打分信息的用户提供较好的推荐结果对用户的进一步使用而言至关重要。这一点严重限制了基于模型的方法在实践中的应用。根本原因在于该方法只考虑物品或者用户之间的直接相似关系。当用户对物品的打分数量相对于整个用户-物品空间而言非常稀疏时, 会出现本来相似的两个物品由于没有被共同的用户打过分而无法被发现的问题。比如, 物品I1和物品I2, 物品I2和物品I3由于被很多相同的用户打过分, 相互之间的相似度值很高。但是由于物品I1和物品I3没有被共同用户打过分, 根据物品打分向量计算出的二者之间的相似度为0。故在搜索物品I1的相似物品时, 会出现物品I3不在其候选相似物品列表中的情况, 但是由于物品I1和物品I2, 物品I2和物品I3具有很好的相似性, 可以推断出物品I1和物品I3也具有一定的相似性。目前已有一些研究成果从不同的角度来改善协同过滤推荐算法的数据稀疏性问题[8, 9, 10]。这些方法有各自的优缺点及其适用范围。其中, 从用户、物品的相似性传递的角度来改善数据稀疏性也受到一些研究者的关注。Huang等[11, 12]通过构建用户-物品二分图, 利用激活-扩散算法进行用户-物品之间的相似性传递, 并通过实验验证了该方法优于基于项目的协同过滤算法及其他经典的协同过滤算法。但是该实验结果只有在数据集比较稀疏的情况下才成立, 否则会产生过度激活问题。Papagelis等[13]根据用户对物品的打分构造用户间的社会网络, 利用用户之间的信任关系的推理进行用户之间的相似性传递。但是该方法是基于用户的协同过滤推荐算法。Nanopoulos等[14]根据用户-物品打分信息构建物品相似网络。该网络是一个有向有权图, 边上的权重为在边的起点物品被评价的条件下, 终点物品被评价的概率。他们针对每一个物品, 定义一个可访问矩阵, 矩阵中的元素为从该物品顶点出发传递到相应终止物品顶点的概率。所以根据该方法计算出的从某一个物品I1传递到物品I3的概率不等于从物品I3传递到物品I1的概率。由于物品是客观实体, 笔者认为两个物品之间的相互相似性应该是相等的。本文借鉴Papagelis等人的思想, 提出了基于物品的相似度传播的协同过滤推荐方法。
2 基于物品的协同过滤推荐算法
基于物品的协同过滤推荐算法是Sarwar等[15]为了克服基于用户的协同过滤推荐算法的可扩展性和无法对推荐结果做出解释这两个问题而提出的方法。该方法类似于基于用户的协同过滤推荐方法, 其基本思想是:为了预测目标用户对物品i的打分, 首先根据物品打分向量计算物品之间的相似度, 然后搜索与物品i最相似的目标用户打过分的前N个物品, 最后根据目标用户对这N个物品的打分预测目标用户对物品i的打分。其本质是一个基于模型的协同过滤推荐算法。关于该算法的具体介绍参见文献[15]。
3 基于启发式的物品相似度传播的协同过滤推荐方法
3.1 物品相似网络
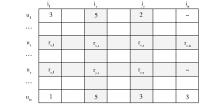
根据用户-物品打分矩阵, 构建物品相似网络的方法如图1和图2所示。其中, 图1是一个用户-物品打分矩阵示例, 图2展示了具体如何构建物品相似网络。
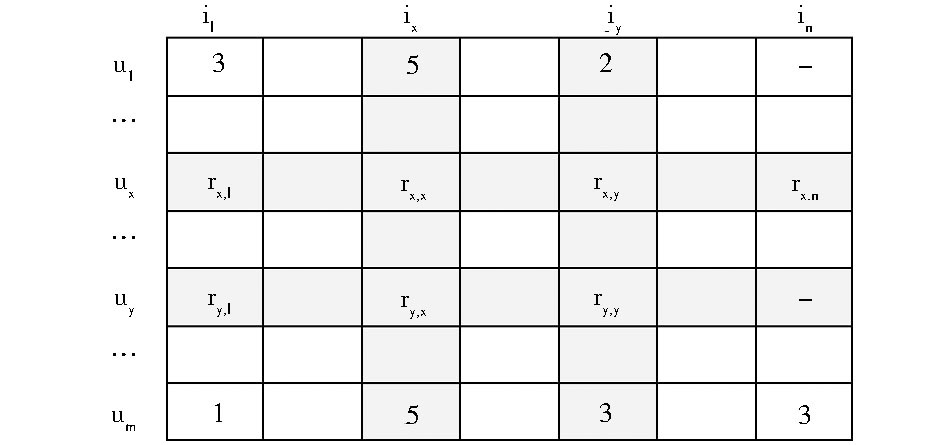 | 图1 用户-物品打分矩阵示例 |
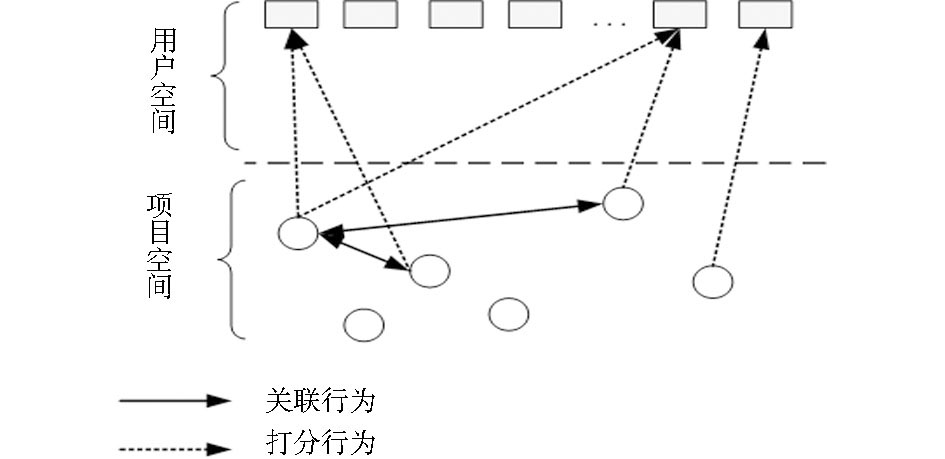 | 图2 物品相似网络的构建 |
物品相似网络具体为一个无向有权图, 图中的每个节点代表物品, 两个物品之间如果被同一个用户打过分, 那么他们之间有边相连, 边上的权重为物品之间的相似度。物品相似网络具有如下性质:
(1)成员性:一个新物品只要至少被一个用户打过分, 那么它就可以加入物品相似网络;
(2)动态性:用户对物品的新打分使得物品之间的新连接关系不断增加。
3.2 相似性传播
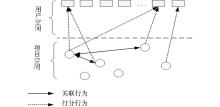
由于在很多推荐系统应用领域, 用户-物品打分矩阵相对于整个用户、物品乘积空间而言非常稀疏。传统的基于物品的协同过滤推荐算法在计算物品之间的相似度时由于信息的缺失, 会造成相似度计算不准确或者出现偏差, 有时甚至会出现与某个物品的相似度值大于0的物品个数少于推荐物品总个数N的情况。本文提出的物品间相似性传播算法能发现更多与目标物品具有一定相似关系的其他物品, 在一定程度上可以改善这个问题。图3可以展示本文的推荐算法的基本思想。
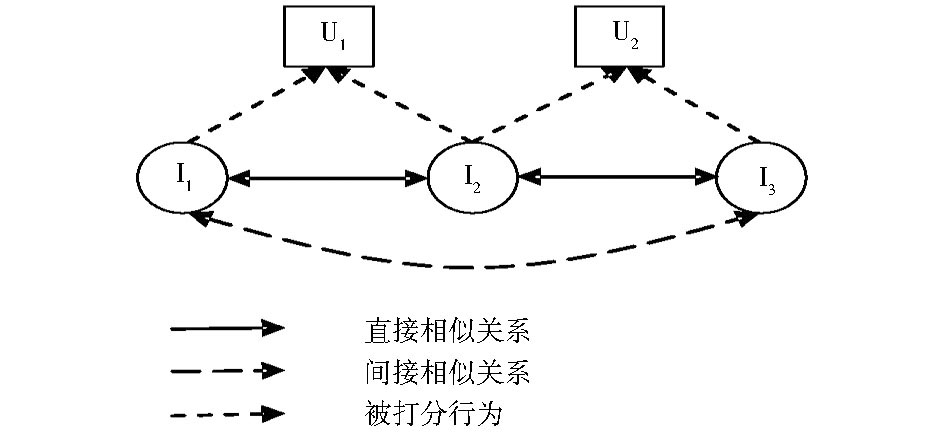 | 图3 相似关系推导 |
假设物品I1和物品I2都被用户U1打过分, 物品I2和物品I3都被用户U2打过分, 但是物品I1和物品I3没有被共同的用户打过分, 那么传统的基于物品的协同过滤推荐算法会认为物品I1和物品I2之间存在相似关系, 物品I2和物品I3之间存在相似关系, 但是物品I1和物品I3之间没有相似关系。本文的推荐算法将识别物品之间的相似性传递关系, 并且度量物品之间的间接相似关系。
定义1:对于物品相似网络中的两个物品I1和I2, 若从物品I1出发存在路径可达物品I2, 那么物品I1和物品I2之间存在相似传递关系, 将可达路径称为相似路径。
定义2:从物品I1到物品I2的相似路径上的直接相似关系的个数, 称为相似路径长度。如图3中I1到I3的相似路径长度为2, I1到I2的相似路径长度为1。
虽然有一定的方法计算相似网络中两个物品之间的直接相似度, 但是需要定义一个传递关系来计算相似路径长度为k的两个物品之间的间接相似度。
定义3:若源物品为I, 目标物品为J, 从物品I到物品J的相似路径上的物品分别为I1, I2, … , Ik, 本文定义物品I和物品J之间的间接相似度为:
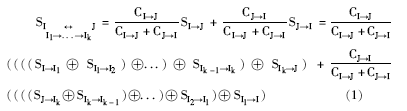
其中, SI→ J表示从物品I传递到物品J的间接相似度; SJ→ I表示从物品J传递到物品I的间接相似度。CI→ J表示对从物品I传递到物品J的间接相似度的确定程度; CJ→ I表示对从物品J传递到物品I的间接相似度的确定程度。该定义的基本思想为, 物品I和物品J的间接相似度为从物品I传递到物品J的间接相似度和物品J传递到物品I的间接相似度的加权和, 权重为相应的确定性占两个传递路径确定性和的比率。
其中, 假定UI1表示对物品I1打过分的用户集合, n(UI1)表示集合UI1中用户数量, 即该集合的势。其中运算符♁的定义为:
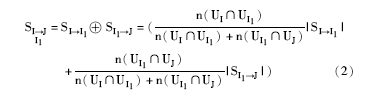
显然, SI→ J的值介于SI→ I1与SI1→ J之间, 并且接近于共同打分用户数较高的值。例如, 若物品I和物品I1有5个用户同时对其打过分且SI→ I1=0.7, 物品I1和物品J有2个用户同时对其打过分且SI1→ J=0.35, 那么SI→ J=0.6。即:
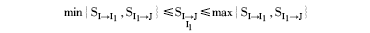
3.3 相似关系的确定性
在社会网络中, 一个人对于他信任的不同的人信任程度不是完全相同的。比如, 若小李直接信任小张, 小张和小王是好朋友并且相互信任, 那么可以推断出小李也会信任小王, 但是可能小李对小王的信任程度没有对小张的信任程度高。基于此思想, 本文认为根据对物品共同打分的用户数量的不同, 物品之间的相似度也具有不同的确定性程度。
定义4:具有直接相似关系的物品I和物品J之间相似性的确定性CI→ J[13]为:
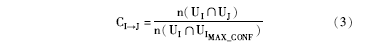
其中, IMAX_CONF表示与物品I的相似度值最大的物品, UIMAX_CONF表示同时对物品IMAX_CONF和物品I共同打分的用户集合。显然, 两个物品的相似关系确定性与同时对他们打过分的用户数量密切相关。这意味着:
(1)若同时对两个物品打过分的用户数量增多, 那么这两个物品之间的相似关系将变得更加可信;
(2)物品I和物品J之间直接相似关系的确定性会随着物品I与其他与其有直接相似关系的物品之间共同打过分的用户数量的变化而变化;
(3)同时对两个物品共同打分的用户数量越多, 那么这两个物品之间的相似关系越可靠。
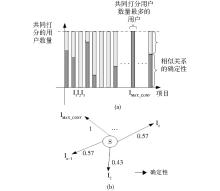
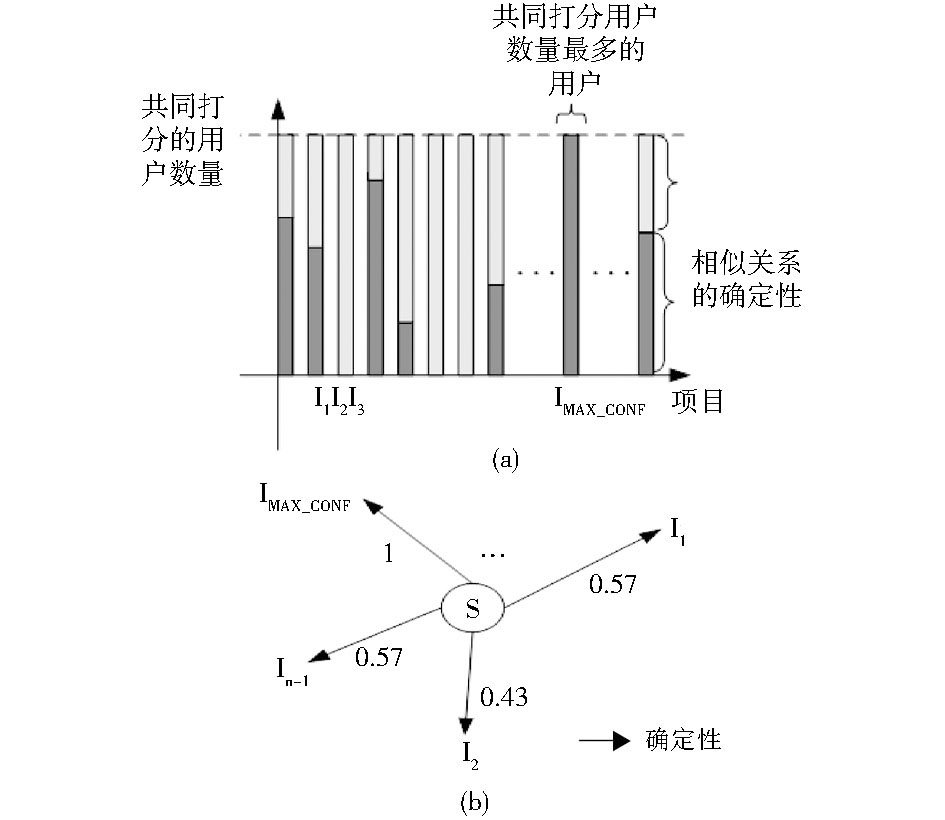 | 图4 物品间相似度的确定性 |
图4展示了两个物品之间直接相似关系的确定性的计算过程。可以看出, 某物品与其最相似的物品之间的相似关系的确定性值总是1, 与其他物品之间直接相似度的确定性小于或等于1(图4(b)所示)。
定义5:若源物品为I, 目标物品为J, 从物品I到物品J的相似路径上的物品分别为I1, I2, … , Ik, 则从物品I传递到物品J的间接相似度的确定性定义[13]为:

定义6:若源物品为I, 目标物品为J, 从物品I到物品J的相似路径上的物品分别为I1, I2, … , Ik, 定义物品I和物品J之间间接相似度的确定性为:
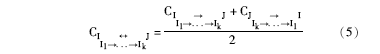
3.4 多个传递路径的管理
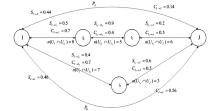
由于物品的相似性传播基于物品相似网络中物品之间的遍历路径, 因此存在两个物品之间有多个遍历路径的情况。图5展示了两个物品I和J之间存在两条遍历路径PA和PB的情况。路径PA经过物品I1和物品I2, 路径PB只经过物品I3。显然, 每条相似路径的相似传播过程是相互独立的。因此, 需要一定的方法来处理物品之间有多个相似传递路径的情况。本文考虑了路径的加权合成和最大确定性路径两种方法作为路径选择策略。
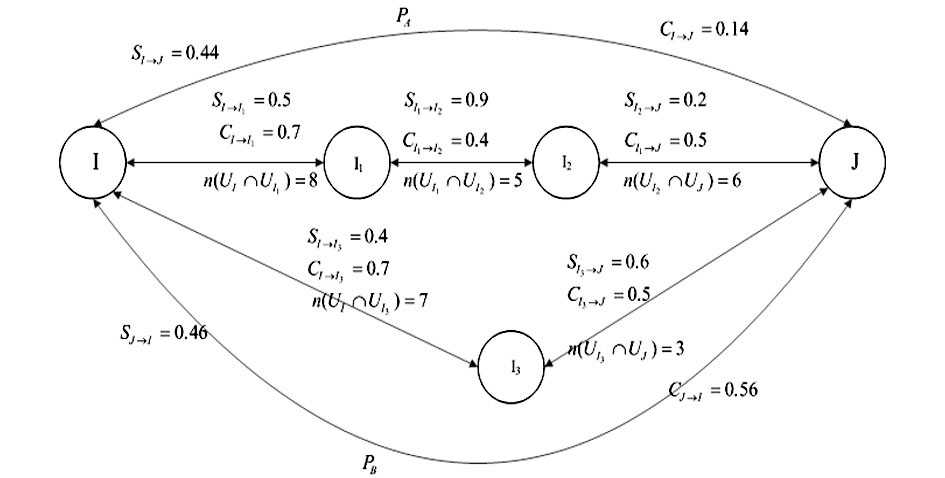 | 图5 多个相似度传递路径 |
(1)路径加权合成(Path Weighted Sum)
该方法取所有遍历路径推导出的间接相似度的加权和, 定义如下所示:

(2)最大确定性路径(Path Maximum Confidence)
该方法选择确定性值最大的那条路径, 定义如下所示:
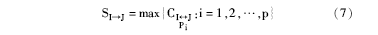
4 实 验
为了验证所提推荐算法的有效性, 在国家科技图书文献中心和Netflix两个数据集上将其与经典的基于用户的协同过滤推荐方法和基于物品的协同过滤推荐方法进行比较。由于Nanopoulos[14]所用的数据集与本文所用的数据集不同, 故没有将本文的算法与其所讨论的算法进行对比。
4.1 实验数据集
(1)第一个数据集是国家科技图书文献中心文献检索系统第三期的用户原文传递订单, 数据集从2010年4月份开始到2012年2月份终止。这里将用户对一篇文献的原文传递请求视为一张订单, 共收集到689 929张订单, 由于很多订单是集体用户的订单, 集体用户的订单是多个用户的原文传递请求信息, 反映了多个用户的兴趣爱好, 无法为其提供个性化推荐服务, 需要将集体用户订单从数据集中清洗掉; 另一方面, 有一些用户的原文传递请求针对日文数据, 由于文献内容相似度计算目前还没有日文数据的处理, 所以这部分订单信息也需要清洗掉。最后共获得44 576张订单信息, 其中包含3 130个用户, 42 774篇文献, 中文文献为16 986篇, 英文文献为27 590篇。针对每一位用户, 选取其下载过的文献集合的70%作为训练集, 余下的30%作为测试集。
(2)第二个数据集是Netflix数据集[17]。Netflix是美国一家提供在线电影租赁服务的公司。用户可以为Netflix上的电影提供评分(包括1, 2, … , 5), 分数越高表示客户对相应电影的评价越高。2006年10月, Netflix对外发布了一个电影评分数据集, 并建立了Netflix Prize竞赛[18]。Netflix Prize所使用的数据集Complete Netflix Prize Dataset(CNPD)通过随机抽取全局评分数据库中的部分用户的评分数据而产生。最终形成的CNPD包括480 189个用户对17 770部电影的103 297 638个评分[19]。针对每一位用户, 选取其下载过的文献集合的80%作为训练集, 余下的20%作为测试集。
4.2 实验结果及分析
图6、图7是两个具体的推荐结果的实例。这里, 为了保护用户的隐私, 将其用户名分别修改为用户A和用户B。
选取MAE和CROC曲线两种度量方式作为实验测度。关于这两个测度的定义参见文献[20]。表1是国家科技图书文献中心数据集上的实验结果。
| 表1 国家科技图书文献中心数据集上的实验结果 |
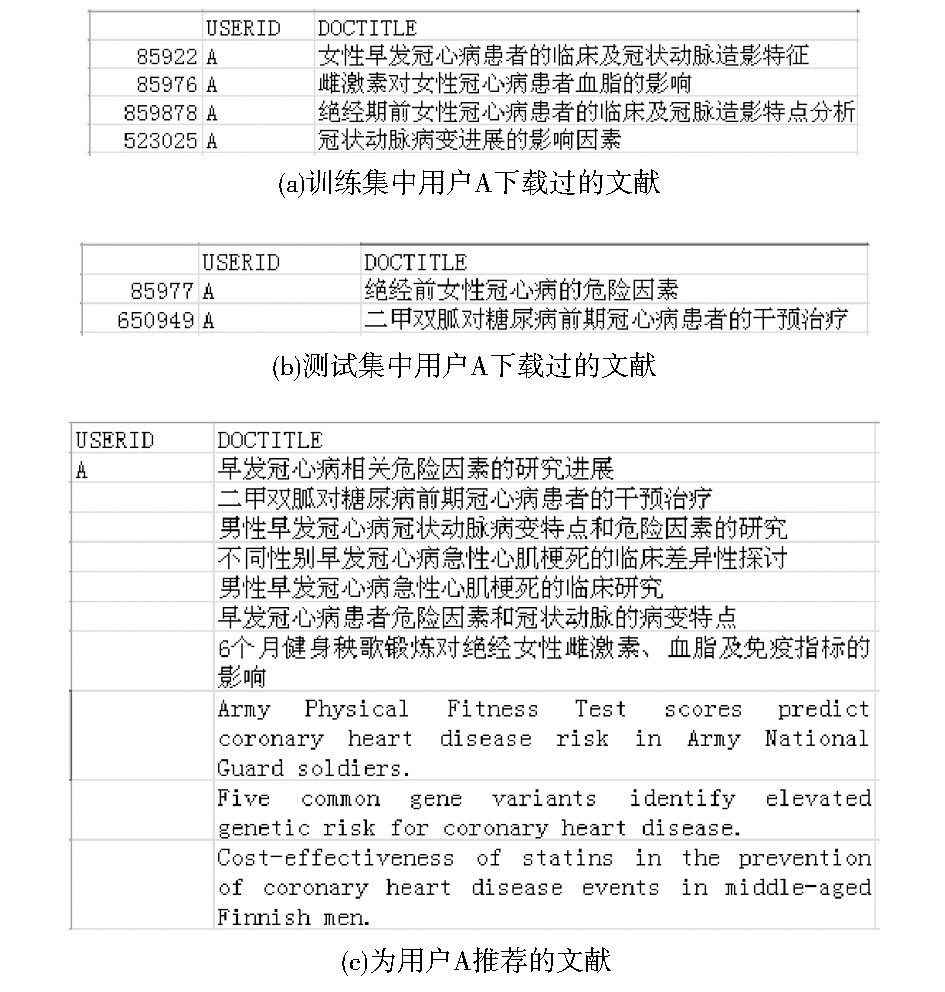 | 图6 为用户A所做的推荐结果示例 |
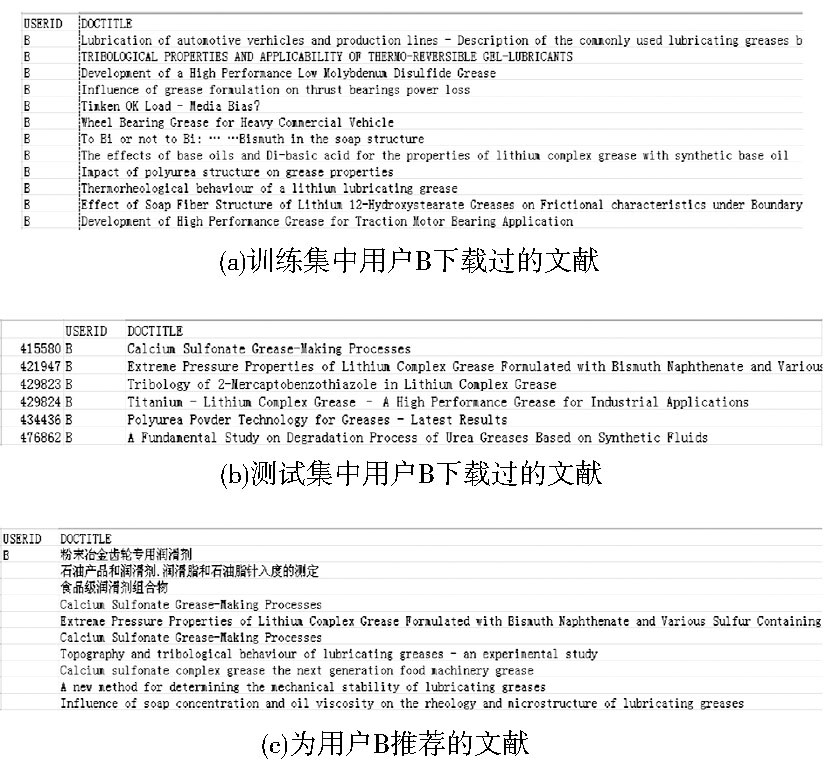 | 图7 为用户B所做的推荐结果示例 |
表2 是Netflix数据集上的实验结果。
| 表2 是Netflix数据集上的实验结果。 |
从实验结果可以看出, 一方面, 本文所提出的基于启发式的物品相似度传播技术能在一定程度上提高传统的协同过滤方法的推荐效果; 另一方面, 当两个物品之间有多个传递路径的时候, 多个传递路径的加权合成方法的效果总体上要优于最大确定性路径的传递路径选择方法。另外, 算法在Netflix数据集上的实验结果要优于国家科技图书文献中心数据集上的实验结果, 这是因为虽然国家科技图书文献中心数据集的规模小, 但是其数据稀疏性比Netflix数据集更加严重, 所以在同一推荐算法的推荐质量上不如Netflix数据集。
5 结 语
为了解决基于模型的物品-物品协同过滤推荐算法只有在用户必须提供充足的对物品的打分时才能提供较好的推荐质量的问题。本文认为在推荐系统领域, 物品之间的相似度也具有传递关系。基于此提出了基于启发式的物品相似度传播的协同推荐方法。该方法可以解决由于数据稀疏性造成的物品间相似关系不能被发现的问题。通过具体的实验验证了该方法的有效性。在未来工作中, 笔者将实现Nanopoulos[14]所提出的算法并基于相同的数据集与本文所提出的算法进行比较。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|